

Microsoft Unveils Phi-2, a Small But Powerful AI Model
Despite not undergoing reinforcement learning alignment, it exhibits promising behavior in toxicity and bias compared to existing open-source models.

Microsoft Research has introduced Phi-2, a remarkable small language model (SLM) with 2.7 billion parameters. Following the success of Phi-1 and Phi-1.5, Phi-2 showcases outstanding reasoning and language understanding, achieving state-of-the-art performance in complex benchmarks, surpassing models 25 times its size.
The Phi series, focusing on strategic training data choices and innovative scaling techniques, challenges conventional language model scaling laws. Notably, Phi-2's performance is comparable to models with higher parameters due to its data mix of high-quality synthetic and filtered web datasets, emphasizing common sense reasoning and general knowledge.
Phi-2's evaluation across various tasks such as math, coding, and common-sense reasoning, indicates superiority over models like Mistral and Llama-2 with larger parameters. Remarkably, it matches or outperforms Google's recently announced Gemini Nano 2, despite being smaller.
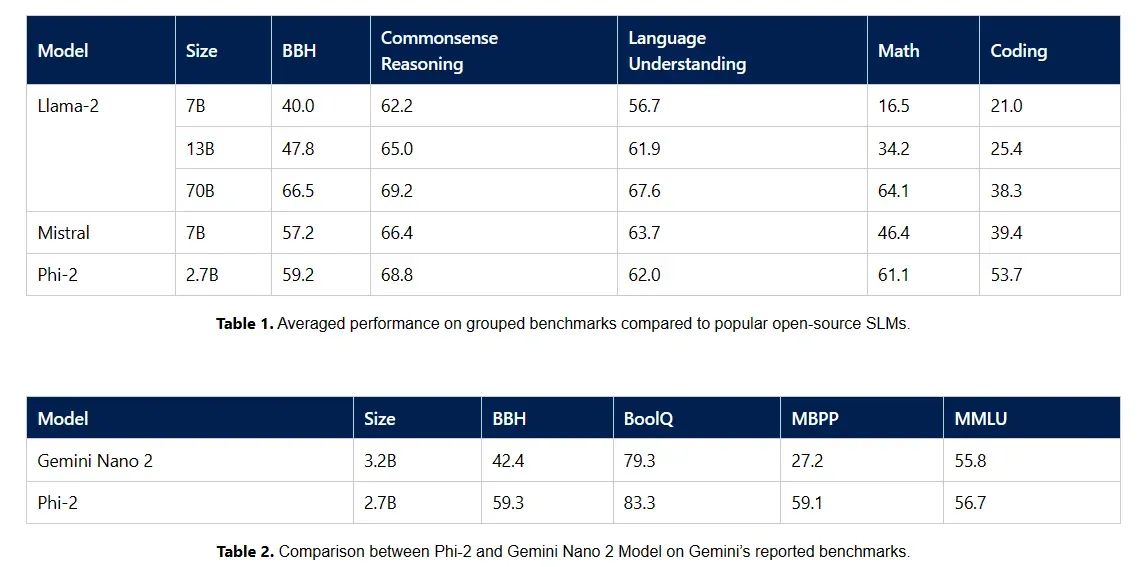
Importantly, Phi-2's training involved 1.4T tokens from synthetic and web datasets for NLP and coding. Despite not undergoing reinforcement learning alignment, it exhibits promising behavior in toxicity and bias compared to existing open-source models.
While model evaluation challenges persist, Phi-2's exceptional performance on academic benchmarks underscores its capabilities and potential for research and development. Microsoft Research has made Phi-2 available in Azure AI Studio to foster language model exploration and innovation.


