

OpenAI Pursues Strategies to Tackle Superintelligent AI
Despite persistent challenges, these findings offer hope for making significant empirical strides in addressing this complex issue today.

In addressing the impending challenge of supervising AI systems significantly surpassing human intelligence, the Superalignment team released a seminal paper detailing an innovative approach to AI alignment. Their groundbreaking method explores whether less potent AI models can effectively supervise and refine the capabilities of more advanced counterparts.
The study's methodology, employing a GPT-2-level model to guide a GPT-4 model, showcased astonishing results. The GPT-4 model, supervised by its weaker counterpart, exhibited performance close to GPT-3.5 levels, demonstrating a remarkable bridge across the capability gap. Notably, the GPT-4 model excelled even in complex tasks where its weaker counterpart faltered, highlighting the potential of this approach to bolster AI capabilities.
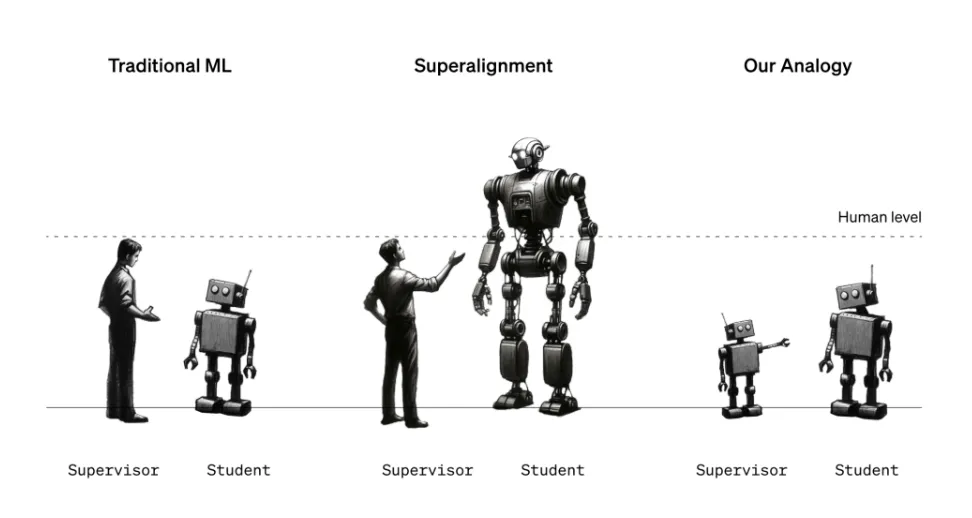
The central strategy involved instilling confidence in the stronger AI model, allowing it to deviate from guidance provided by the weaker supervisor. While the approach displayed notable limitations, such as challenges with ChatGPT preference data, it notably enhanced the performance of the GPT-4 model.
Acknowledging disparities between the empirical setup and the ultimate challenge of aligning future superhuman models, this research marks an essential starting point. Despite persistent challenges, these findings offer hope for making significant empirical strides in addressing this complex issue today.
However, the concept of Superalignment remains contentious within the AI research community. While some view it as premature, others suggest it's a misleading diversion from immediate AI regulatory issues like algorithmic bias and toxicity.
Leopold Aschenbrenner highlighted the urgency, stating, "AI progress recently has been extraordinarily rapid, and I can assure you that it’s not slowing down. So how do we align superhuman AI systems and make them safe? It's really a problem for all of humanity — perhaps the most important unsolved technical problem of our time."
the Superalignment team has open-sourced their code, inviting researchers to explore weak-to-strong generalization experiments. Additionally, they have launched a $10 million grants program, empowering scholars and graduate students to delve deeper into the realm of superhuman AI alignment, with a focus on refining weak-to-strong generalization.
In a world where superhuman AI systems are on the verge of realization, this research signifies a pivotal step in understanding and harnessing their potential. Amidst ongoing challenges, these discoveries offer a glimpse into steering future AI innovations towards safety and reliability.
The urgency of aligning superhuman AI has never been greater. With these breakthroughs, the AI landscape is poised for unprecedented advancements, ensuring that humanity can harness the immense potential of AI safely and ethically.


