

Stability AI Unveils Stable Code 3B An Offline-Ready AI Coding Assistant
The model is intended to be used as a foundational base model for application-specific fine-tuning. Developers must evaluate and fine-tune the model for safe performance in downstream applications.

Stability AI has introduced Stable Code 3B, the latest addition to its lineup of AI-assisted software development models, marking a significant stride in the field. This 2.7 billion parameter decoder-only language model is pretrained on an extensive 1.3 trillion tokens from diverse textual and code datasets. What sets this model apart is its capability to run offline on standard laptops without a GPU, offering developers unparalleled flexibility and efficiency.
Key Features of Stable Code 3B:
- Efficient Performance: Despite its compact size, Stable Code 3B boasts 60% of the performance of larger models like Code Llama 7B. This breakthrough in efficiency enables developers to harness the power of AI coding assistance without the need for extensive hardware.
- Training Foundation: Built upon Stability AI's foundational 3-billion parameter Stable LM, the model undergoes additional training on over 4 trillion tokens of software engineering data. This strategic training enhances its proficiency and adaptability in real-world coding scenarios.
- Offline Capabilities: One of the standout features of Stable Code 3B is its ability to run offline on laptops, providing developers with a private and seamless coding experience. This is particularly advantageous for scenarios where internet access may be limited, or security concerns are paramount.
- Context Expansion: Stable Code 3B supports expanded context lengths, reaching up to 100,000 tokens—significantly surpassing its training length of 16,384 tokens. This extended context handling empowers the model to navigate and auto-complete complex code structures.
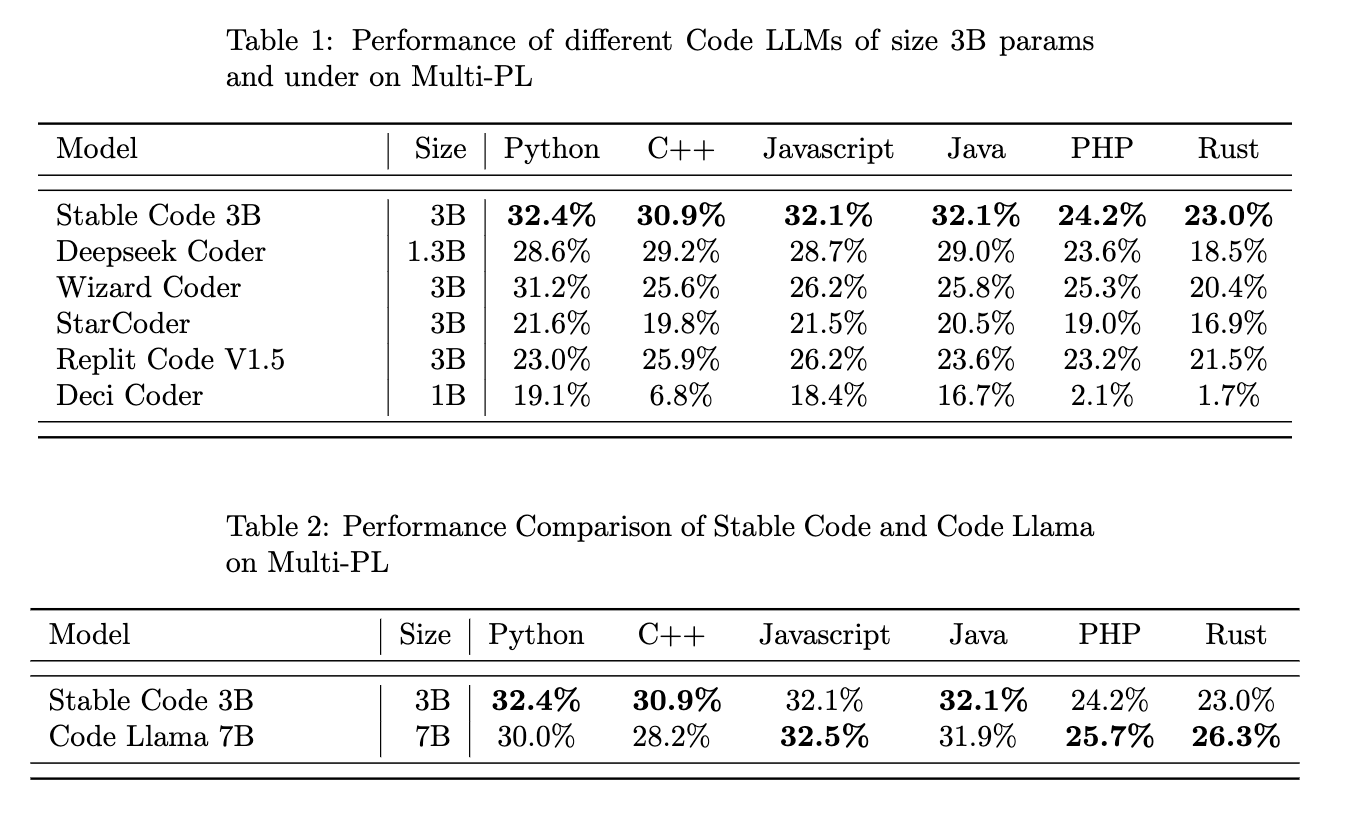
State-of-the-Art Performance Across Languages:
Stable Code 3B shines across 18 programming languages, showcasing state-of-the-art proficiency based on the MultiPL-E benchmark. This evaluation demonstrates the model's prowess in handling sophisticated, multi-file projects and providing context-aware solutions in languages such as Python, Javascript, and more.
Limitations and Bias
As a base model, this model may exhibit unreliable, unsafe, or other undesirable behaviors that must be corrected through evaluation and fine-tuning prior to deployment. The pre-training dataset may have contained offensive or inappropriate content, even after applying data cleansing filters, which can be reflected in the model-generated text. We recommend that users exercise caution when using these models in production systems. Do not use the models if they are unsuitable for your application, or for any applications that may cause deliberate or unintentional harm to others.


